第一章:什么是作用域?
几乎所有编程语言的最基本范式之一都是将值存储于变量中,并在以后可以访问或修改这些值。实际上,正是这种对变量存取值的能力才使得程序具有 状态。
当然,即使没有这个概念,程序也可以执行某些任务,但是会受到极大的限制,也会失去很多乐趣。
在程序中引入变量带来了一系列我们现在要讨论的有趣问题:这些变量 存在 于哪里?换言之,它们保存在哪里?最重要的是,当我们的程序需要用它们时该如何找到它们?
这些问题说明我们需要一套完善的规则来规定变量的存储位置以及需要时如何找到这些变量。我们把这套规则称为:作用域。
但是,我们在何处以及如何设置这些作用域规则呢?
编译器理论
尽管JavaScript通常被归类为“动态”或“解释型”语言,但是实际上它是一门编译型语言。读者可能觉得这是不言而喻的,也可能感到很惊讶,这取决于你对各类语言的掌握程度。与许多传统编译型语言和各种分布式系统中跨平台编译结果不同的是,JavaScript不会预先编译好。
虽然与其他传统语言编译器相比,JavaScript引擎以比我们通常了解的更复杂的方式执行代码,但是它们执行的很多步骤是一样的。
在传统的语言编译过程中,你的程序,一大堆源代码,在被执行前会经历三个主要步骤,大致称为“编译”:
标记化/分词:将一串字符串拆分成(对这门语言来说)有意义的小块,称为标记。例如,对于程序:
var a=2;,可能会被拆分成下列标记:var,a,=,2和;。如果标记中的空白有意义,则会保留,否则就会被去掉。注: 标记化(Tokenizing)和分词(Lexing)的区别微乎其微,主要区别是这些标记是以 无状态 方式还是以 有状态 方式被识别。简而言之,如果分词器根据有状态解析规则来判断
a应该是一个单独的标记,还是仅仅是另一个标记的一部分,那么这种方式就是 分词。解析:将标记流(数组)转换为代表程序语法结构的嵌套元素树。这棵树称为“AST”(Abstract Syntax Tree 抽象语法树)。
var a=2;的AST的顶层节点称为VariableDeclaration,它有两个子节点:一个是Identifier(值为a);另一个是AssignmentExpression,它又有一个子节点称为NumbericLiteral(值为2)。代码生成:将AST转换为可执行代码的过程。该步骤根据不同语言、不同目标平台而有很大不同。
因此,这里我们不具体展开细节,只需要知道通过某种方法将上文所述的“var a=2;”的AST转换成了一组机器指令,这组指令才实际上创建了一个变量a(包括分配内存等),然后在a中保存了一个值。
注:引擎是如何管理系统资源的知识超出了我们的学习范畴,因此我们只需知道引擎能够创建和保存变量即可。
和大多数其他语言编译器一样,JavaScript引擎的工作比上述的三个步骤复杂的多。例如,在解析和代码生成阶段,肯定需要有消除冗余元素等优化执行性能的步骤。
因此,这里我只简略提及,但是我相信读者很快就会明白我们为什么要从一个相对高的层面介绍这些细节。
还有一点需要注意,JavaScript引擎没有多余的时间(其他语言编译器则有)来做优化,因为JavaScript编译不像其他语言一样提前在构建时编译。
对JavaScript来说,大多数情况下编译发生在代码被执行前几微秒(或更少)内。JS引擎使用了很多的技巧来保证最快的性能(如进行懒编译、甚至热重新编译的JITs等),这些技巧超出了我们讨论的“作用域”的范畴。
简单来说,任何JavaScript代码片段都必须在它被执行之前(通常就在之前)被编译。因此,JS编译器处理程序时,会先对他进行编译,然后再准备执行它,通知是立马就执行。
理解作用域
我们把学习作用域的方法想像成交谈的过程,那么,由谁来进行交谈呢?
演员表
我们先来认识处理程序var a = 2;过程中的几个角色,以便我们理解马上将要听到的对话:
- 引擎:负责整个编译过程和执行JavaScript程序
- 编译器:引擎的朋友之一;处理解析和代码生成等脏活累活
- 作用域:引擎的另一个朋友;收集并维护由所有声明的标识符(变量)组成的查询表,对当前执行的代码如何访问这些变量强加一系列严格的规则 如果你想 彻底理解 JavaScript是如何工作的,那么你需要从引擎的角度,想其所想,问其所问,答其所答。
来来回回
第一眼看到程序var a = 2;,你很可能认为它是一条语句。但是我们的新朋友引擎可不是这么认为的。实际上,引擎会把它当作两条不同的语句,其中一条编译器在编译时会处理,另一条引擎在执行时会处理。
现在我们分开来看引擎和它的朋友们是怎么处理程序var a = 2;的。
拿到这个程序后,编译器做的第一件事是分词,把程序拆分成各个标记,然后将它们解析成语法树。但是当编译器到代码生成阶段时,它处理这个程序的方式可能与我们设想的不一样。
一个合理的解释是编译器会综合这样的伪代码:“给一个变量分配内存,将其命名为a,然后把值2保存到这个变量中”来生成代码。很遗憾,这是不准确的。
其实,编译器会这样处理:
- 遇到
var a时,编译器询问作用域是否在特定的作用域范围中已经存在变量a。如果存在,编译器忽略这条声明语句并继续向前执行。否则,编译器要求作用域在其范围内声明一个新的变量a。 - 然后编译器生成供引擎执行的代码来处理赋值语句
a = 2。引擎运行的代码会先询问作用域在当前作用域范围内是否存在一个可被访问的变量a。如果存在,引擎就用这个变量;如果不存在,引擎会到别的地方去找(参见下文的嵌套作用域)。 如果引擎最终找到了这个变量,则把值2赋给这个变量。如果没有找到,引擎会举手并大喊出错了!
总结:变量赋值被当作两个不同的行为:首先,编译器声明一个变量(如果在当前作用域中还未被声明),然后在执行的时候,引擎在作用域中查找这个变量,如果找到便对其赋值。
编译器发言
为进一步理解编译器工作原理,我们需要了解更多相关术语。
当引擎在执行步骤(2)中编译器生成的代码时,它会去查询变量a是否已经被声明,而这个查找过程会咨询作用域。但是引擎执行的查找类型会影响查找结果。
在我们这个例子中,引擎会用“LHS”方式来查找变量a,另一种查找方式是“RHS”。
我想你应该能猜到“L”和“R”表示的意思。这两个属于表示“Left-hand Side”和“Right-hand Side”。当然,这里的左边和右边是 相对赋值操作符来说的。换言之,当变量出现在赋值操作的左边时进行LHS查找,当变量出现在赋值操作的右边时进行RHS查找。
实际上,更准确的表述应该是:RHS查找仅仅是查找某些变量的值,然而LHS查找会尝试找到变量容器本身,这样才能进行赋值操作。这样一来,RHS本身不真正表示“赋值的右边”,而仅仅表示,准确的说是,“非左边”。
我们说得更巧妙一点,可以认为“RHS”表示“检索他/她的源头(值)”,也就是说RHS表示“去获得...的值”。
我们在深入一点。 当我说:
console.log(a);
对a的引用是一个RHS引用,因为这里没有任何东西赋给a。因此,我们通过查找取得a的值,然后将这个值传给console.log(...)。
作为对比:
a = 2;
这里对a的引用是一个LHS引用,因为我们并不关心当前值是什么,我们只是想找到这个变量作为赋值操作=2的目标。
注:LHS和RHS表示“赋值操作的左/右”,不一定是字面意思表示的“赋值操作符的左/右边”。赋值还有其他几种方式,因此最好从概念上区分:“谁是赋值操作的目标(LHS)”,而“谁是赋值操作的源(RHS)”。
考虑下面即有LHS又有RHS的程序:
function foo(a) {
console.log( a ); // 2
}
foo( 2 );
最后一行把foo(...)作为函数调用进行调用时,要求一个对foo的RHS引用,表示,“去找到foo的值并给我”。另外,(...)表示foo的值要被执行,因此实际上它最好是一个函数!
这里有一个容易忽略但是很重要的赋值操作,你发现了吗?
你可能没有发现这段代码中隐式的a=2。值2作为参数传递给foo函数,在函数中值2被赋给参数a。(隐式地)给变量a赋值执行的是LHS查找。
上面的代码还对a进行了一次RHS引用,取得a的值并传递给console.log(...)。console.log(...)需要执行一个引用。执行RHS查找console对象,然后进行属性分析查找是否有一个叫做log的方法。
最后,我们从概念上理解,将值2传递(通过变量a的RHS查找)给log(...)会发生一次LHS/RHS交换。我们可以假设log(...)的原生实现中会接收参数,而在将2赋给第一个参数(可能称为arg1)时,会先进行一个LHS查找。
注:从概念上,可以把函数声明function foo(a) {...}当作一个普通的变量声明和赋值,如var foo和foo = function(a){...}。这样的话,可以认为这个函数声明中包含一个LHS查找。然而,一个细微但是很重要的区别是,编译器在代码生成阶段会同时处理声明和值定义,所以当引擎执行代码时,无需将函数值赋给foo。因此将函数声明视为一个LHS查找赋值不是恰当的。
引擎/作用域 对话
function foo(a) {
console.log( a ); // 2
}
foo( 2 );
我们把上述的交换(执行这个段代码)想象为一次对话。那么这次对话应该会是这样的:
引擎:嘿 作用域, 我这里有一个
foo的RHS引用,你听说过吗?作用域:当然听过。 编译器 刚刚声明了它。它是一个函数,给你。
引擎:太好了,谢谢你! OK,我现在执行
foo.引擎:嘿, 作用域, 我这里有一个
a的LHS引用,你听说过吗?作用域:当然听过。 编译器 刚刚把他声明为
foo的一个形参,给你。引擎:一如既往地乐于助人, 作用域,再次谢谢你. 现在,是时候把
2赋给a了.引擎:嘿, 作用域, 抱歉再次打扰你。 我需要
console的RHS查找。你听说过吗?作用域:没关系, 引擎, 这是我的本职工作。我这里有
console,它是一个内置对象,给你。引擎:太好了。 找一下
log(..)。 OK, 太好了, 它是一个函数。引擎: 喲, 作用域. 你能帮我RHS引用到
a吗?我记得有它,只不过想确认下。作用域: 你是对的 引擎。跟刚才的是同一个家伙,给你。
引擎:太酷了。 把
a的值2传递给log(..)。...
小测试
现在检查下到目前为止你是否完全理解了。一定要扮演引擎的角色与作用域进行交谈:
function foo(a) {
var b = a;
return a + b;
}
var c = foo( 2 );
- 指出所有的LHS查找(有3个!)
- 指出所有的RHS查找(有4个!)
嵌套作用域
我们说过 作用域 是一组通过标识符名字查找变量的规则。然而,通常需要考虑的作用域不止一个。
就如一个代码块或函数嵌套在另一个代码块或函数内,作用域也可以被嵌套在另一个作用域中。因此,如果在最近的作用域中找不到某个变量,引擎会在外一层的作用域中去查找,直到找到或达到最外层作用域(也即,global)。
考虑:
function foo(a) {
console.log( a + b );
}
var b = 2;
foo( 2 ); // 4
在函数foo中无法解析变量b的RHS引用,但是在外层的作用域(这里是全局作用域global)中能够被解析。
因此,再看一下引擎和作用域的对话,我们会偷听到:
引擎:“嘿,foo函数的作用域,听说过b吗? 我这里有一个对它的RHS引用。”
作用域: “没,没听过,去钓鱼吧。”
引擎:“嘿,foo函数外层的作用域,噢,你是全局作用域。你听说过b吗?我这里有一个对它的RHS引用。”
作用域:“有的,给你”
遍历嵌套作用域的简单规则:引擎首先在当前正在执行的作用域查找这个变量,如果没有找到的话,则往上一层查找,如此往复。如果到达了最外层的全局作用域,不管找到这个变量还是没有,查找都会停止。
比喻成高楼
为了形象展示嵌套作用域的解析过程,可以想象下面这栋高楼:
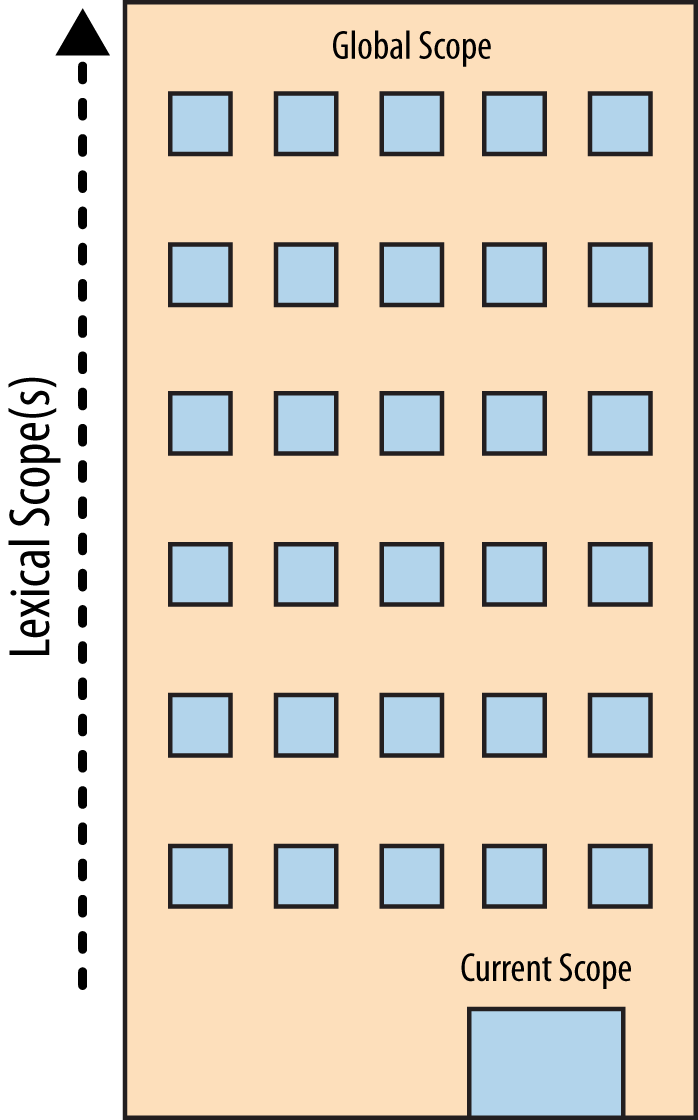
这栋楼表示程序的嵌套作用域。第一层表示当前正在执行的作用域,不管在哪里,顶层是全局作用域。我们在当前楼层查找来解析LHS和RHS引用,如果没有找到,就坐电梯到上一层去查找,然后再到上一层。一旦到达顶层(全局作用域),要么找到我们正在查找的东西,要么没有找到。但无论如何都要停止继续查找。
错误
为什么我们用LHS还是RHS查找会对结果有影响呢?
因为这两种类型的查找在变量还没有被声明的环境中(在任何作用域都没有找到)的行为机制不同。 例如:
function foo(a) {
console.log( a + b );
b = a;
}
foo( 2 );
当第一次对b进行RHS查找时,将找不到它,也就是说它是一个“未被声明”的变量,因为在作用域中找不到它。
如果RHS查找在嵌套作用域中的任何地方都没有找到某个变量,引擎会抛出一个ReferenceError。重要的是要记住这个错误是ReferenceError类型。
相比之下,如果引擎执行LHS查找,到达顶层(全局作用域)时仍没找到某个变量,且程序不是在“严格模式”下执行的话,那么全局作用域就会在 全局作用域 中新建这个变量,然后把它返回给引擎。
“我这里之前没有,但是我很乐意为你创建一个。”
ES5中引入的“严格模式”与正常/松散/懒惰模式相比有很多不同的行为表现。其中一个就是它不允许自动/隐式创建全局变量。在我们这个例子中,没有全局的变量返回给LHS查找,引擎会抛出一个与RHS情况相同的错误ReferenceError。
现在,如果RHS查找找到了某个变量,但是如果你对这个值做一些它不能做的事情,如把一个非函数值作为函数执行,对null或undefined值引用其属性,这时候引擎会抛出另一种类型的错误“TypeError”。
ReferenceError是作用域解析失败相关的错误,而TypeError表明作用域解析成功,但是尝试对解析结果进行非法/不可能的操作。
复习
作用域是一组规定变量(标识符)保存在哪里、如何查找到它的规则。通过这种查找可以给一个LHS(Left-hand-side)引用的变量赋值,也可以获取某个RHS(Right-hand-side)引用的变量的值。
LHS引用来自赋值操作。作用域相关的赋值随着=操作符出现,也可以出现在给函数传参时。
JavaScript引擎首先在代码执行前编译,在这个过程中,它把像var a = 2;这样的语句分成下面两个步骤:
- 首先,通过
var a在作用域中声明变量,这是在一开始就进行的,在代码执行之前; - 然后,
a = 2会去查找这个变量(LHS引用),如果找到就给他赋值。
LHS和RHS引用查询都是从当前执行的作用域开始查找,如果需要(即在这里没有找到需要的变量),则按照嵌套作用域的方式,一层一层向上查询,直到到达全局作用域,不管找没找到都停止查找。
未成功的RHS引用会抛出ReferenceError,未成功的LHS引用则会自动隐式的创建一个全局变量(非“严格模式”下),或抛出ReferenceError(严格模式下)。